
이론
Connection Pool이란
애플리케이션에서 데이터베이스로 연결하기
많은 웹 애플리케이션에서 DB를 활용한다.
하지만 애플리케이션에서 DB를 연결하는 것은 상당히 비용이 많이 드는 작업이다.
- 연결에 필요한 객체의 JVM GC 처리
- TCP 연결 생성/종료의 I/O 처리 : 주로 DB와 연결할 때 TCP 통신을 하는데, TCP 통신은 연결 시 3 way-handshake, 연결 종료 시 4 way-handshake 과정을 거친다. 이 과정에서 통신 비용이 많이 소모된다.
DB 연결 비용을 줄일 방법이 없을까?
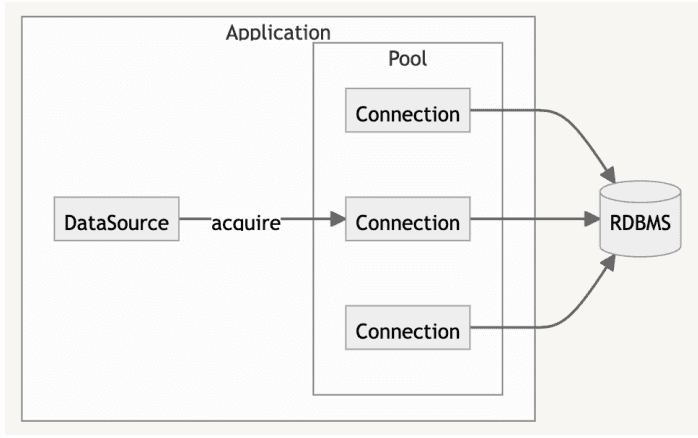
 하나의 DataSource가 요청을 보내어 Connection을 생성하고, 소켓을 만들어 RDBMS와 연결하는 과정
하나의 DataSource가 요청을 보내어 Connection을 생성하고, 소켓을 만들어 RDBMS와 연결하는 과정
Connection Pooling이란?
: DataSource 객체를 통해 미리 커넥션(Connection)을 만들어 두는 것을 의미한다.
- 미리 DB에 연결한 객체를 재사용하면 커넥션을 새로 생성하는 데 드는 비용을 줄일 수 있다.
- Connection 객체를 모아둔 컨테이너를 Connection Pool이라고 부른다.
- Connection Pool에 만들어둔 커넥션은 재사용할 수 있다.
- 사용 가능한 커넥션 객체가 없고, 최대 크기에 도달하지 않았다면 새 커넥션을 만든다.

Pooling vs. No Pooling
정말로 Connection Pooling이 더 빠를까?
실습 코드를 통해 Pooling 방식과 No Pooling 방식이 각각 몇 초가 걸리는지 확인해보자.
*iftop 명령어로 네트워크 트래픽을 모니터링할 수 있다.
다음은 Connection 요청을 1,000개 실행하는 테스트 코드이다.
class PoolingVsNoPoolingTest {
private final Logger log = LoggerFactory.getLogger(PoolingVsNoPoolingTest.class);
private static final int COUNT = 1000;
private static MySQLContainer<?> container;
@BeforeAll
static void beforeAll() throws SQLException {
// TestContainer로 임시 MySQL을 실행한다.
container = new MySQLContainer<>(DockerImageName.parse("mysql:8.0.30"))
.withDatabaseName("test");
container.start();
final var dataSource = createMysqlDataSource();
// 테스트에 사용할 users 테이블을 생성하고 데이터를 추가한다.
try (Connection conn = dataSource.getConnection()) {
conn.setAutoCommit(true);
try (Statement stmt = conn.createStatement()) {
stmt.execute("DROP TABLE IF EXISTS users;");
stmt.execute("CREATE TABLE IF NOT EXISTS users (id INT AUTO_INCREMENT PRIMARY KEY, email VARCHAR(100) NOT NULL) ENGINE=INNODB;");
stmt.executeUpdate("INSERT INTO users (email) VALUES ('hkkang@woowahan.com')");
conn.setAutoCommit(false);
}
}
}
@AfterAll
static void afterAll() {
container.stop();
}
@Test
void noPoling() throws SQLException {
final var dataSource = createMysqlDataSource();
long start = ClockSource.currentTime();
connect(dataSource);
long end = ClockSource.currentTime();
// 테스트 결과를 확인한다.
log.info("Elapsed runtime: {}", ClockSource.elapsedDisplayString(start, end));
}
@Test
void pooling() throws SQLException {
final var config = new HikariConfig();
config.setJdbcUrl(container.getJdbcUrl());
config.setUsername(container.getUsername());
config.setPassword(container.getPassword());
config.setMinimumIdle(1);
config.setMaximumPoolSize(1);
config.setConnectionTimeout(1000);
config.setAutoCommit(false);
config.setReadOnly(false);
final var hikariDataSource = new HikariDataSource(config);
long start = ClockSource.currentTime();
connect(hikariDataSource);
long end = ClockSource.currentTime();
// 테스트 결과를 확인한다.
log.info("Elapsed runtime: {}", ClockSource.elapsedDisplayString(start, end));
}
private static void connect(DataSource dataSource) throws SQLException {
// COUNT만큼 DB 연결을 수행한다.
for (int i = 0; i < COUNT; i++) {
try (Connection connection = dataSource.getConnection()) {
try (Statement stmt = connection.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM users")) {
if (rs.next()) {
rs.getString(1).hashCode();
}
}
}
}
}
private static MysqlDataSource createMysqlDataSource() throws SQLException {
final var dataSource = new MysqlDataSource();
dataSource.setUrl(container.getJdbcUrl());
dataSource.setUser(container.getUsername());
dataSource.setPassword(container.getPassword());
dataSource.setConnectTimeout(1000);
return dataSource;
}
}noPooling()의 테스트 결과:

pooling()의 테스트 결과:
 Connection Pool을 사용해서 9초->2초로 5배 가량 성능이 향상된 것을 확인할 수 있다.
Connection Pool을 사용해서 9초->2초로 5배 가량 성능이 향상된 것을 확인할 수 있다.
이번엔 커넥션의 개수를 1,000개에서 10,000개로 늘려보자.
noPooling()의 테스트 결과:

pooling()의 테스트 결과:
 Connection Pool을 사용해서 70초->8초로 9배 가량 성능이 향상된 것을 확인할 수 있다.
Connection Pool을 사용해서 70초->8초로 9배 가량 성능이 향상된 것을 확인할 수 있다.
이처럼 커넥션 개수가 늘어날수록 Connection Pool을 사용했을 때와 사용하지 않았을 때의 성능 차이는 기하급수적으로 늘어난다.
Connection Pooling 사용하기
- Connection pool도 여러 구현체가 존재한다.
-
현재 대세는 HikariCP
-
다른 구현체에 비해 속도가 매우 빠르고, 높은 동시성을 보장한다.
-> Spring Boot가 기본 Connection Pool로 HikariCP를 사용하는 이유.
-
직접 빈으로 커스텀해서 사용할 수도 있다.
-
- Supported Connection Pools
- Configure a Custom DataSource
- Spring Hibernate with Annotations

Connection Pool 구성 설정하기
Configuration, HikariCP 공식 문서를 참고하여 HikariCP를 설정해보자.
-
HikariCP의 필수 설정은 다음과 같다.
dataSourceClassNameorjdbcUrldataSourceClassName: JDBC Driver가 제공하는 DataSource 클래스의 이름.jdbcUrl: DriverManager 기반 구성을 사용하도록 명시하는 속성. 보통 DataSource 기반의 구성이 더 좋다고 하지만 사실 큰 차이는 없다.
username: 기본 드라이버에서 Connection을 가져올 때 사용되는 기본 인증 사용자의 이름을 설정하는 속성.password: 기본 드라이버에서 Connection을 가져올 때 사용되는 기본 인증 암호를 설정하는 속성.
-
자주 사용되는 설정은 다음과 같다.
autoCommitconnectionTimeoutidleTimeoutkeepaliveTimemaxLifetimeconnectionTestQueryminimumIdlemaximumPoolSize: 유휴 커넥션과 사용중인 커넥션을 포함해 Pool이 가질 수 있는 최대 크기를 설정하는 속성. 이 값에 따라 DB 백엔드에 대한 실제 최대 연결 수가 결정된다.(기본 값: 10)metricRegistryhealthCheckRegistrypoolName
-
HikariCP를 사용할 때 적용하면 좋은 MySQL 설정
jdbcUrl=jdbc:mysql://localhost:3306/simpsons username=test password=test dataSource.cachePrepStmts=true dataSource.prepStmtCacheSize=250 dataSource.prepStmtCacheSqlLimit=2048 dataSource.useServerPrepStmts=true dataSource.useLocalSessionState=true dataSource.rewriteBatchedStatements=true dataSource.cacheResultSetMetadata=true dataSource.cacheServerConfiguration=true dataSource.elideSetAutoCommits=true dataSource.maintainTimeStats=false- 데이터 캐싱과 관련된 옵션
cachePrepStmts: 이 속성 값이 true로 설정되면 MySQL의 PreparedStatement Caching 기능이 활성화된다.(기본값 false)prepStmtCacheSize: MySQL 드라이버가 Connection 당 캐시할 준비된 쿼리 구문 수를 설정한다.(기본 값 25) 250에서 500 사이로 설정하는 것이 좋다.prepStmtCacheSqlLimit: MySQL 드라이버가 캐싱할 PreparedStatement의 최대 길이.(기본값 256) 권장 설정은 2048이다.useServerPrepStmts: Server-Side PreparedStatement를 사용하는 옵션.
- 데이터 캐싱과 관련된 옵션
적절한 pool 사이즈 구하기
해당 문서에 포함된 실습 영상에서, 커넥션 풀의 크기를 줄였을 때 오히려 성능이 더 개선된 것을 확인할 수 있다.
CPU는 여러 스레드의 작업을 동시에 수행하기 위해 컨텍스트 스위칭이라는 기술을 사용해 여러 개의 작업을 동시에 처리한다. 하나의 CPU 리소스가 주어졌을 때, A와 B를 순차적으로 실행하는 것이 타임 슬라이싱을 통해 A와 B를 동시에 실행하는 것보다 빠르다. 그렇기 때문에 스레드 수가 CPU 코어 수를 초과하게 되면, 스레드가 많아질 수록 성능이 빨라지기는 커녕 느려지게 된다.
커넥션 풀의 상황도 이와 비슷한데, 몇가지 다른 요인도 함께 작용한다. DB의 주요 병목 현상은 크게 CPU, 디스크, 네트워크 3가지 범주로 요약할 수 있다.
-
CPU
디스크, 네트워크적인 요인을 무시했을 때, 코어가 8개인 서버에서 커넥션의 수를 8개로 설정하면 최적의 성능을 제공할 수 있고, 그 이상이 되면 컨텍스트 스위칭의 오버헤드로 인해 성능이 느려지기 시작한다. 하지만 디스크와 네트워크적 요인이 더해지면 생긴다.
-
디스크
데이터베이스가 다른 쿼리의 데이터를 읽기/쓰기하려면 디스크의 읽기/쓰기 헤드를 새로운 위치로 이동시켜야 하는데, 이 때 탐색 시간에 대한 비용이 발생한다.
이 시간(=I/O 대기)동안 커넥션/쿼리/스레드는 차단되고(블로킹), 그동안 OS는 다른 스레드에 대한 코드를 더 실행하여 해당 CPU의 컴퓨팅 리소스를 더 잘 사용할 수 있다.
때문에 실제로는 물리적인 CPU 코어 수보다 많은 수의 커넥션&스레드를 보유함으로써 더 많은 작업을 수행할 수 있다. 이 개수는 디스크 서브 시스템에 따라 달라지는데, 최신 SSD 드라이브는 하드 디스크와 달리 물리적인 회전에 의한 탐색 비용 등이 없기 때문에 CPU 코어 수에 가까운 개수의 스레드일 때 더 나은 성능을 발휘할 수 있다.
즉 블로킹으로 인해 실행 기회가 생기는 경우엔 코어 수보다 더 많은 스레드를 사용하는 것이 더 나은 성능을 발휘할 수 있다.
-
네트워크
이더넷 인터페이스를 통해 유선으로 데이터를 쓰는 경우, 송수신 버퍼가 가득 차서 멈출 때 블로킹이 발생할 수 있다.
-
PostgreSQL가 추천하는 Connection Pool Size를 구하는 공식은 다음과 같다.
connections = ((core_count * 2) + effective_spindle_count)예제 ) 하드 디스크가 1개 있는 4코어 i7 서버에 대해 이를 계산하면
9=((4*2)+1)와 같은 결과를 얻을 수 있다. 즉, 약 10개의 커넥션을 가지도록 하는 것이 성능적으로 좋을 것이라 예측할 수 있다.
-
커넥션 풀 교착 상태
교착 상태를 피하기 위한 커넥션 풀의 최소 크기는 다음과 같은 공식으로 얻을 수 있다.
pool size = Tn x (Cm - 1) + 1 여기서 Tn은 최대 스레드의 수이고, Cm은 단일 스레드가 동시에 보유할 수 있는 최대 Connection 수이다.
예제 ) 어떤 작업을 수행하는 데 각각 4개의 연결이 필요한 3개의 스레드가 있다고 하자.(Tn=3, Cm=4) 교착 상태가 절대 발생하지 않도록 하는데 필요한 풀 크기는 3x(4-1)+1=10개이다.
교착 상태(Dead Lock)
스레드가 서로의 DB Connection이 반납되기만을 무한정 대기하는 상황 예제 )
- 스레드는 총 4개가 있고 DBCP의 크기는 2이다.
- 스레드 하나당 작업을 수행하는 데 필요한 커넥션의 개수는 2개이다.
- 1번 스레드와 2번 스레드가 작업을 수행하기 위해 DBCP로부터 커넥션을 1개씩 받아온다.
- 1, 2번 스레드는 1개의 커넥션만으로는 작업을 수행할 수 없기 때문에 다른 스레드로부터 1개의 커넥션이 반납될 동안 기다리게 된다.
- 그동안 3, 4번 스레드는 커넥션을 얻지 못해 Exception이 발생한다.
- 하지만 DBCP의 상태는 total=2, active=2, idle=0, waiting=0이므로, 반납될 커넥션이 존재하지 않는다. 즉, 1, 2번 스레드는 서로의 커넥션이 반납되기를 기다리는 상황이다.
-> 데드락 발생
실습
0. DataSource 다루기
Java에서 제공하는 JDBC 드라이버를 통해 데이터베이스에 연결하는 방법을 실습 코드로 알아보자.
DriverManager
JDBC 드라이버를 관리하는 가장 기본적인 방법.
커넥션 풀, 분산 트랜잭션을 지원하지 않아 잘 사용하지 않는다.
JDBC 4.0 이전에는 Class.forName 메서드를 사용해 JDBC 드라이버를 직접 등록해야 했는데, JDBC 4.0부터는 DriveManger가 적절한 JDBC 드라이버를 찾아준다.
class Stage0Test {
private static final String H2_URL = "jdbc:h2:./test";
private static final String USER = "sa";
private static final String PASSWORD = "";
@Test
void driverManager() throws SQLException {
// Class.forName("org.h2.Driver");
try (final Connection connection = DriverManager.getConnection(H2_URL, USER, PASSWORD)) {
assertThat(connection.isValid(1)).isTrue();
}
}
}DataSource
데이터베이스, 파일 같은 물리적 데이터 소스에 연결할 때 사용하는 인터페이스.
구현체는 각 vendor에서 제공한다.
테스트 코드의 JdbcDataSource 클래스는 h2에서 제공하는 클래스이다.
...
@Test
void dataSource() throws SQLException {
final JdbcDataSource dataSource = new JdbcDataSource();
dataSource.setURL(H2_URL);
dataSource.setUser(USER);
dataSource.setPassword(PASSWORD);
try (final var connection = dataSource.getConnection()) {
assertThat(connection.isValid(1)).isTrue();
}
}
}Drivermanager 대신 DataSource를 사용하는 이유
- 애플리케이션 코드를 직접 수정하지 않고 Properties 설정으로 DB 연결 설정을 변경할 수 있다.
- 커넥션 풀링(Connection pooling) 또는 분산 트랜잭션은 DataSource를 통해서 사용 가능하다.
1. 커넥션 풀링
H2에서 제공하는 JdbcConnectionPool을 직접 다루어보자.
class Stage1Test {
private static final String H2_URL = "jdbc:h2:./test;DB_CLOSE_DELAY=-1";
private static final String USER = "sa";
private static final String PASSWORD = "";
@Test
void testJdbcConnectionPool() throws SQLException {
final JdbcConnectionPool jdbcConnectionPool = JdbcConnectionPool.create(H2_URL, USER, PASSWORD);
assertThat(jdbcConnectionPool.getActiveConnections()).isZero();
try (final var connection = jdbcConnectionPool.getConnection()) {
assertThat(connection.isValid(1)).isTrue();
assertThat(jdbcConnectionPool.getActiveConnections()).isEqualTo(1);
}
assertThat(jdbcConnectionPool.getActiveConnections()).isZero();
jdbcConnectionPool.dispose();
}
}아래 코드를 보면 HikariCP를 사용하기 위한 필수 속성인 jdbcUrl, username, password를 설정해주고, MaximumPoolSize는 5로 설정한 것을 확인할 수 있다.
DataSource 설정으로는 cachePrepStmts를 true로 설정해서 캐시를 사용하도록 설정했고, prepStmtCacheSize는 250, prepStmtCacheSqlLimit은 2048로 설정했다.
이렇게 자바 코드로도 HikariCP의 프로퍼티를 설정해줄 수 있다.
@Test
void testHikariCP() {
final var hikariConfig = new HikariConfig();
hikariConfig.setJdbcUrl(H2_URL);
hikariConfig.setUsername(USER);
hikariConfig.setPassword(PASSWORD);
hikariConfig.setMaximumPoolSize(5);
hikariConfig.addDataSourceProperty("cachePrepStmts", "true");
hikariConfig.addDataSourceProperty("prepStmtCacheSize", "250");
hikariConfig.addDataSourceProperty("prepStmtCacheSqlLimit", "2048");
final var dataSource = new HikariDataSource(hikariConfig);
final var properties = dataSource.getDataSourceProperties();
assertThat(dataSource.getMaximumPoolSize()).isEqualTo(5);
assertThat(properties.getProperty("cachePrepStmts")).isEqualTo("true"); assertThat(properties.getProperty("prepStmtCacheSize")).isEqualTo("250"); assertThat(properties.getProperty("prepStmtCacheSqlLimit")).isEqualTo("2048");
dataSource.close();
}
}2. HikariCP 설정하기
Spring Boot로 HikariCP를 설정하는 방법을 알아보자.
설정 파일 application.yml을 사용해 DataSource를 설정할 수 있다. DataSource를 여러 개 사용하거나 세부 설정을 해주고 싶은 경우 빈을 직접 생성하는 방법을 사용할 수 있다.
다음 코드는 DataSource를 직접 빈으로 생성하는 Configuration 코드이다.
@Configuration
public class DataSourceConfig {
public static final int MAXIMUM_POOL_SIZE = 5;
private static final String H2_URL = "jdbc:h2:./test;DB_CLOSE_DELAY=-1";
private static final String USER = "sa";
private static final String PASSWORD = "";
@Bean
public DataSource hikariDataSource() {
final var hikariConfig = new HikariConfig();
hikariConfig.setPoolName("gugu");
hikariConfig.setJdbcUrl(H2_URL);
hikariConfig.setUsername(USER);
hikariConfig.setPassword(PASSWORD);
hikariConfig.setMaximumPoolSize(MAXIMUM_POOL_SIZE);
hikariConfig.setConnectionTestQuery("VALUES 1");
hikariConfig.addDataSourceProperty("cachePrepStmts", "true");
hikariConfig.addDataSourceProperty("prepStmtCacheSize", "250");
hikariConfig.addDataSourceProperty("prepStmtCacheSqlLimit", "2048");
return new HikariDataSource(hikariConfig);
}
}커넥션 풀의 크기를 5로 설정해주었다.
이제 다음 코드를 실행하여 DataSource 객체에 직접 생성한 빈이 주입되었는지 확인해보자.
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
class Stage2Test {
private static final Logger log = LoggerFactory.getLogger(Stage2Test.class);
@Autowired
private DataSource dataSource;
@Test
void test() throws InterruptedException {
final var hikariDataSource = (HikariDataSource) dataSource;
final var hikariPool = getPool((HikariDataSource) dataSource);
// 설정한 커넥션 풀 최대값보다 더 많은 스레드를 생성해서 동시에 디비에 접근을 시도하면 어떻게 될까?
final var threads = new Thread[20];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(getConnection());
}
for (final var thread : threads) {
thread.start();
}
for (final var thread : threads) {
thread.join();
}
// 동시에 많은 요청이 몰려도 최대 풀 사이즈를 유지한다.
assertThat(hikariPool.getTotalConnections()).isEqualTo(DataSourceConfig.MAXIMUM_POOL_SIZE);
// DataSourceConfig 클래스에서 직접 생성한 커넥션 풀.
assertThat(hikariDataSource.getPoolName()).isEqualTo("gugu");
}
private Runnable getConnection() {
return () -> {
try {
log.info("Before acquire ");
try (Connection ignored = dataSource.getConnection()) {
log.info("After acquire ");
quietlySleep(500);
}
} catch (Exception e) {
}
};
}
public static HikariPool getPool(final HikariDataSource hikariDataSource)
{
try {
Field field = hikariDataSource.getClass().getDeclaredField("pool");
field.setAccessible(true);
return (HikariPool) field.get(hikariDataSource);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}테스트가 모두 통과하여, 우리가 정의해준 DataSource 객체를 사용하고 있음을 확인할 수 있었다.
한 가지 중요한 지점이 있는데, 크기가 5인 커넥션 풀에 대해, 20개의 스레드가 동시에 커넥션을 요청하고 있는데 이 코드는 어떻게 동작하게 될까?
위 테스트코드의 실행 결과 일부를 캡쳐해보았다.
 After acquire 메시지가 뜬다는 것은 해당 스레드가 Connection을 얻었다는 의미와 같다.
After acquire 메시지가 뜬다는 것은 해당 스레드가 Connection을 얻었다는 의미와 같다.
20개의 스레드가 초기화되면서 Before acquire 메시지를 출력하고, 5개의 스레드가 Connection을 얻은 것을 확인할 수 있다.(노란 수평선 위쪽의 빨간 동그라미들)
그리고 그로부터 0.5초마다 5개씩의 스레드가 Connection을 얻는 모습을 확인할 수 있다.
이로부터 알 수 있는 사실은 스레드의 개수가 Connection Pool Size보다 클 경우, 커넥션 풀의 모든 커넥션이 다른 스레드에 의해 할당된 상태라면 나머지 스레드는 커넥션이 반납될 때까지 대기상태에 들어간다는 것이다.
참고 자료
HikariCP Dead lock에서 벗어나기[이론편] HikariCP Dead lock에서 벗어나기[실전편] HikariCP를 MySQL에 맞게 튜닝하기